Roughly 5 years ago, our founders spearheaded identifying an issue with the UK’s current classification system (SIC Codes). We’ve since worked as a team to build a platform to overcome that problem.
SIC codes lacked a real-time element and could not accurately/reliably define the emerging economy. Today, our UK platform allows any user to build any definition of an industry in seconds.
Among many applications, our tech has notably been used to shape innovation clusters and support DSIT to drive a national vision for engineering biology. However, our customers kept asking whether our data had international coverage and our answer was always “no”. And just like that, the stage was set for our next big leap.
Quick heads up, this is a pretty long in-depth article so here’s a TL;DR:
Initial Planning
Before we started building anything, we had to ask ourselves (and our customers) a few key questions:
- What is our mission statement?
- What is our vision statement?
- Where will we get the data from?
- What should the global product look like?
- What are the key features?
- What will RTICs look like?
- How many countries will be initially covered?
- How will we overcome issues with language differences?
Fortunately for me, the bosses had already provided answers to questions #1 and #2.
#1 Mission
At The Data City, our mission is “to build the new standard industrial classification system”. We’re developing a unique company database built on modern search and machine learning classifications. Our Real-Time Industrial Classifications (RTICs) move beyond the limitations of static industry data reliant on outdated SIC codes.
#2 Vision
Our vision is “liberation from SIC to find and invest in the industries that address the world’s key challenges and opportunities”.
There’s an incredible amount of power in having the mission and vision statements clearly laid out before anything actually starts being built.
The dev team and I have a completely transparent view as to why we’re building the global product and what the end goal of doing so is. There’s nothing worse than starting dev work without knowing exactly what you need to build.
#3 Sourcing the data
This was pretty easy for us. We already have a great partnership with our friends at Creditsafe. They were able to supply us with a bulk global file delivered via an SFTP system making our data ingestion both easy to automate and fast.
We could apply some quick transformations to suit our usage and Creditsafe have great coverage of some of our priority countries (such as the US).

Creditsafe do a brilliant job at standardising company records and financials which means it’s easy to interpret the data.
In our current version of the global product, we’re using the websites supplied by Creditsafe to power our RTICs. This is a key difference (at this stage!) to our UK product where we’ve undergone a hefty URL matching process to improve reliability in our data, especially in RTIC classifications.
3a) Sourcing the data: Technical Implementation
Our ingestion pipeline runs in a few stages using standard Extract, Tranform, Load (ETL) processes.
We connect to the SFTP and use Data Version Control (DVC) to establish whether anything has changed upstream and then run the transform, load elements of the ETL process if required. This is all written in python and uses pipenv to manage dependencies.
Our ingestion pipeline uses black for formatting and leverages the power of GitHub actions for CI/CD. The output pushes a zipped version of an SQLite database to blob storage. Later downstream, this is converted to a DuckDB.
In some of our latest revisions to other data pipelines, we’ve switched to poetry and ruff. We’ll get around to that on this one.
#4 Aesthetics
Again, a pretty easy decision to be made on the UI of the global platform.
Our UK users have familiarity with how the platform works so there’s no need to over-complicate things. We’ve made it look extremely similar to our UK platform with a goal to achieve almost the same level of functionality.
4a) Aesthetics: Technical Implementation
Similarly, the implementation of the global platform frontend is closely related to our UK product.
The core of the product is built using HTML, CSS and vanilla JS. PHP is also used to create dynamic page content. This relatively simple setup gives us good site performance and fast page load times. We can also develop, test, and release new features quickly across a range of related products.
Data requests from the frontend are handled through a custom PHP middleware layer which manages user authentication. Responses from the backend server are sent through a JSON based REST API.
#5 Key Features
We made a list of the key features we needed to build as quickly as possible to make the global platform usable:
1. Ability to view and filter company details in ‘Explore’
1.1. RTIC filter
1.2. Country filter
1.3. Legal form
1.4. Company search
1.5. Financials
1.5.1. Turnover range
1.5.2. Employee range
1.6 Keyword search of company website text
2. Ability to summarise and visualise results in ‘Analyse’
2.1. Summary
2.1.1. Total number of companies
2.1.2. Total turnover
2.1.3. Total Employees
2.2. Country distribution
2.3. Company legal form counts
5a) Key Features: Backlog
The following is a list of already identified data & features that we are planning to release into the product throughout the Global Alpha 6-month period. However, as this is new and contains unknowns on a very large scale of data, we cannot commit to any/all of this just yet.
- Addition of ML list building features
- Additional CreditSafe company data
- RTIC summary tab
- QA of CreditSafe URL matches
- Additional of new URL matches
- Join of Dealroom data
- Join of Lightcast data
- Additional Analyse widgets/features/data
5b) Key Features: Technical Implementation
Most of these we were able to build quite quickly once we had the data. However, all these features are nothing without maintaining a level of speed a user can extract insights from.
We explored a few different ways of powering our platform, such as a beefy postgres instance, however we settled on harnessing the power of clickhouse. Clickhouse states they are “the fastest and most resource efficient open-source database for real-time apps and analytics” and we’ve basically found that to be true. It’s an incredibly powerful tool.
Our global database currently holds roughly 110m companies (only a small 2100% increase compared our UK product!). With this volume of data and the nature of our database queries, a traditional RDBMS (Relational Database Management System) wasn’t going to cut it. Simple operations such as count queries were taking minutes when we needed seconds.
Transitioning to Clickhouse gave us the performance improvement we needed, especially for areas of the product such as Analyse, which needs to aggregate vast amounts of data in a timely fashion.
Alongside Clickhouse we also have a Redis caching layer, which helps to improve the response times of commonly used filters and queries.
#6 RTICs
One of our biggest challenges once we’ve sourced website text for global companies is to assign RTICs to global companies. There are a few ways we can think about this:
- English language UK RTICs applied to global companies (live in the product)
- English language localised RTICs
- Localised RTICs (including foreign languages)
- Global RTICs
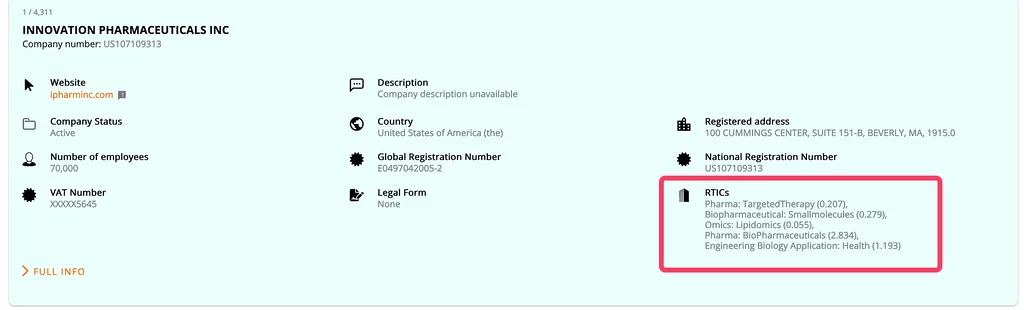
Our ethos is to ship early and often, get features/data live on the platform as soon as the data is in a ‘good enough’ shape. Our key goal was to get #1 complete as quickly as possible with a confidence in the accuracy of the data. We can always improve on this and roll-out #2-4 when we have added machine learning list building functionality (next 6-8 weeks).
It’s important to understand that’s currently what our global RTICs are. We’ve worked really hard building RTICs in the UK and we’ve applied these classifications to global companies. There’s three key elements to this and Net Zero is a great example:
- Taxonomy. Net Zero in the UK will not have the taxonomy as Net Zero in Germany. For example, nuclear power. The UK considers nuclear power to be contributing to Net Zero targets however Germany does not. We would include nuclear in our taxonomy, Germany would not.
- Difference in English language. Net Zero in the UK is not the same as Net Zero in the US. Despite the UK and US both using English language, the US talks about Net Zero in a different way.
- Difference in language. Applying an English language built classifier to Germany may not transfer very well. Most German websites will be using German language hence an English built classifier may not classify as reliably.
These are all fantastic problems for us to work with our partners/customers to overcome. We’re on the road to building the best industrial classification engine and we invite our users to support us with these challenges.
6a) RTICs: Technical Implementation
We put in a place a system which allows us to take the classifiers for our UK product and apply them to our global companies. Since we have roughly 400 RTIC verticals in our UK product, that’s 400 classifiers. We used these to classify roughly 11m websites in 25 hours.
This is no small task but thankfully we were able to take a lot of learning from the UK system and apply similar principles to the global product. Initially we pre-process the company web text into a format which can then be utilised by the machine learning process. You can read more about our machine learning classification on our knowledge base.
Once we have the data in the appropriate format, our classifying script can then analyse millions of companies, against our models, and within seconds produce a relevance score. The output data is then loaded directly into the global process, providing the end users with a list of RTICs.
#7 Countries and #8 Languages
We’re initially covering 12 countries including the UK and we’ll be talking about language differences in another blog post. I’ve covered it a bit in the RTIC section but it’s a whole new landscape for us to explore over the next 12 months and beyond.
Summary
All of this technical implementation has led to us being able to offer a global product. To be clear, the global product is not the UK product. The UK product has taken us almost 5 years to get to where it is today and we’re really proud of it. We’re now actively on the road to building the best global industry engine and that means nailing the global product.
It’s a major leap for our business, we’re super grateful to our customers for their support and interest in helping us to build the right solution for our market. The greatest debt in a tech start-up is building data and features that customers don’t want or need. This project is designed to help us avoid these pitfalls and build the best possible solution for our customers!
If you’d like to find out more about our global platform and register your interest in our Alpha programme, you can find out more and sign up via our Global page.