Welcome to the second post in our new series, where we lift the lid on the journey of developing our Industry Engine. In this post, we’re giving you a behind-the-scenes glimpse into how we crafted our improved ‘similar companies’ feature. This improvement is set to elevate the usability of our platform, making it more intuitive and making it easier and quicker for users to gain powerful insights.
Missed the first post in the series? Check it out here
A much better similar companies feature
In January 2022 we released a similar companies feature. For 448 thousand companies we listed up to five similar companies.
This feature was useful to many users but had some problems that prevented many use cases from being served. Specifically,
- Similar companies often used similar words to the original company but did very different things.
- Companies that did similar things but described them using slightly different language were not found to be similar.
We are very happy to announce today that we have solved many of these problems. We can now show at least five similar companies for the vast majority of our 1.7 million companies with websites.

Semantic search
Our original similarity scoring method compared words that were present on company websites, with very common words such as “and”, “the”, “it”, etc… removed. This meant that a shop selling vinyl records would appear similar to a gym helping people train to set personal weightlifting records.
Our new approach using semantic search and LLM-based methods understands that the meaning of “record” in these two examples is different and will no longer score record shops as similar to gyms.
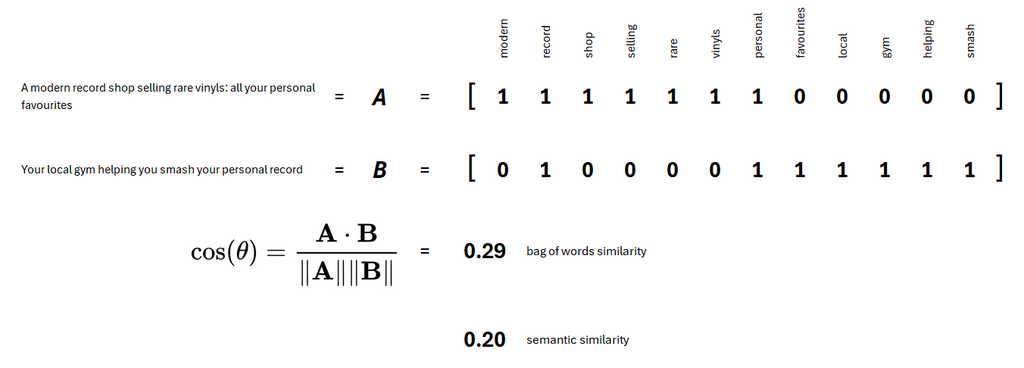
“A modern record shop selling rare vinyls: all your personal favourites” scores similarly to “A personalised gym helping you set your personal record” using a bag of words cosine similarity approach. A semantic similarity approach understands that the two phrases are less similar than they seem, but the detailed feature vector is not interpretable by a human.
Semantic search also does better where two companies do similar things but describe them in different ways. Many companies talk about recruiting on their websites. This means that the presence of the word recruiting on a website is not an effective way to identify recruiting firms.
Much more powerful are the presence of phrases such as “headhunting,” “talent acquisition,” and “candidate sourcing” but with a wide range of such phrases it is rare that anyone will be found across all recruiters’ websites. Semantic search fixes this problem because it understands that these three phrases, and many more, mean similar things.

“Award-winning headhunters: providing the best candidates to suit your bespoke staffing requirements” has absolutely no similarity with “A leading talent acquisition service finding people for the tricky roles you struggle to fill” using a bag of words cosine similarity approach. A semantic similarity approach understands that the two phrases are remarkably similar. The detailed feature vector for both phrases used in the semantic similarity approach is not interpretable by a human.
Why this doesn’t replace machine learning
Our improved similar companies feature makes it much easier to find similar companies. It does not replace our machine learning approaches to building lists.
Our ML Lists and Real-Time Industrial Classification (RTIC) approach considers the similarity and dissimilarity of all companies to a training set of dozens of companies. This approach consistently finds many more companies, within a much tighter sector definition, with a much lower error rate.
Our ML Lists approach has another advantage too. While our new similarity feature works well, we can’t always explain why. In the short examples we’ve given here we can work backwards to explain similarities, but when considering the whole web presence of a company this is almost impossible. While such a black box approach to similarity is great for one-off similarities searches, it isn’t good for defining sectors and building larger lists of companies.
Next steps
We are working on this feature heavily in the coming months. We have a plan to improve similarity scoring further and some ideas of where this feature could accelerate and improve current processes such as building ML Lists and building our Industry Engine.
If you have any feedback on the quality of our similarity scores or any suggestions for new features, we could enable with them please let us know.
Want to try it out for yourself? Sign up to a free trial here.