Starting my UK career as a master’s student in Data Science, my course was structured in a way that allowed me to work for a year in my field of interest. I have always aimed to work in a startup, as I enjoy growing with the product and the team.
A few months into the job, Jack introduced me to the world of Large Language Models (LLMs), which was the hot topic in the tech industry. Tech giants such as Meta, Google, and OpenAI were launching their own models, and the tech industry was overwhelmed with the possibilities of LLMs.
In case you didn’t know, in very simple terms, an LLM is an AI model based on a tremendous amount of data. This lets the LLM “understand” and generate human-like text.
Having access to the website text of 1.6m companies and knowing my interest in programming, I was assigned to explore this field and its possibilities. Without knowing where this project would take us, we started exploring LLMs with The Data City’s data.
There’s a lot of potential in LLMs for The Data City. Imagine having a smart buddy that can instantly give you the lowdown on companies, get insights on competitors, navigate regulations, and even handle customer chats with a personal touch.
That’s what we’re up to with our LLM experiments. We’re all about making the nitty-gritty of data analysis fun and useful for businesses, making sure you’ve got the insights and automation to make informed moves.
It’s all about turning ‘what-ifs’ into ‘what’s next’, making data less of a headache.
Before we begin
We took a random sample of 1,000 companies from the 1.6 million that we have scraped website text for. Keeping the numbers down allowed us to experiment and learn far more quickly.
We also needed a library, as well as an LLM. For our initial experiments, we ended up choosing Langchain, an open-source library which was vital for providing the LLM framework, alongside the GPT-4 LLM.
Experimentation
Firstly, we needed to prep the data. To cut a long and technical story short, we converted our 1,000 companies into vectors. Vector embeddings are a way to convert words and sentences and other data into numbers that capture their meaning and relationships.
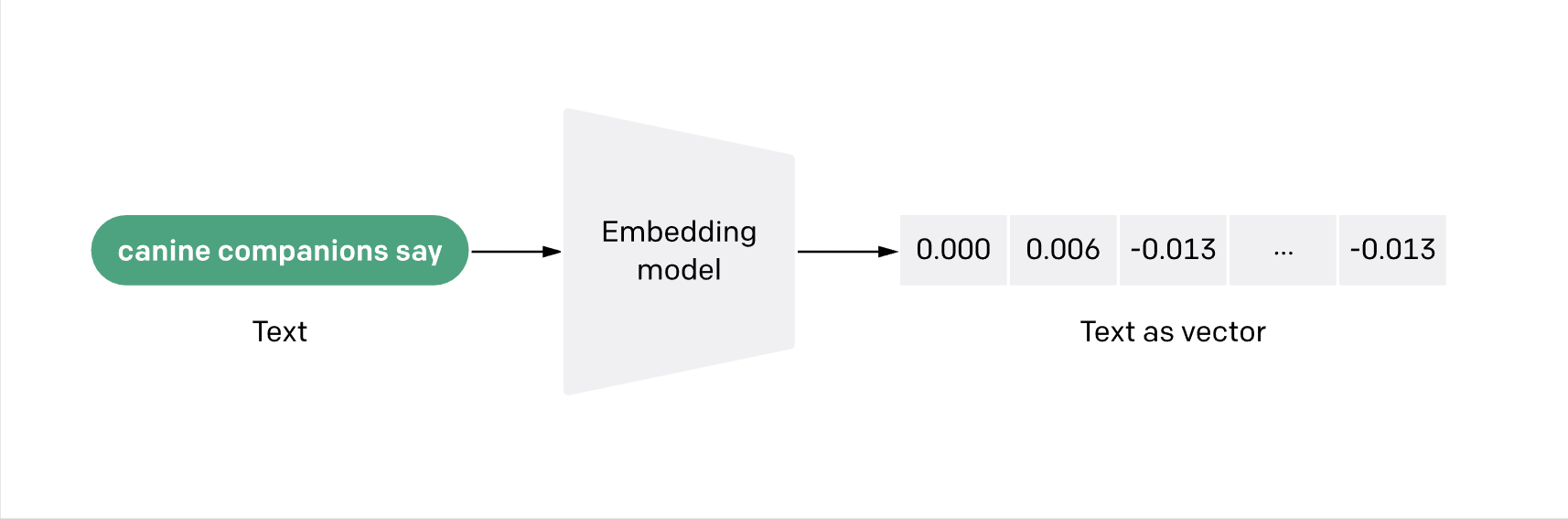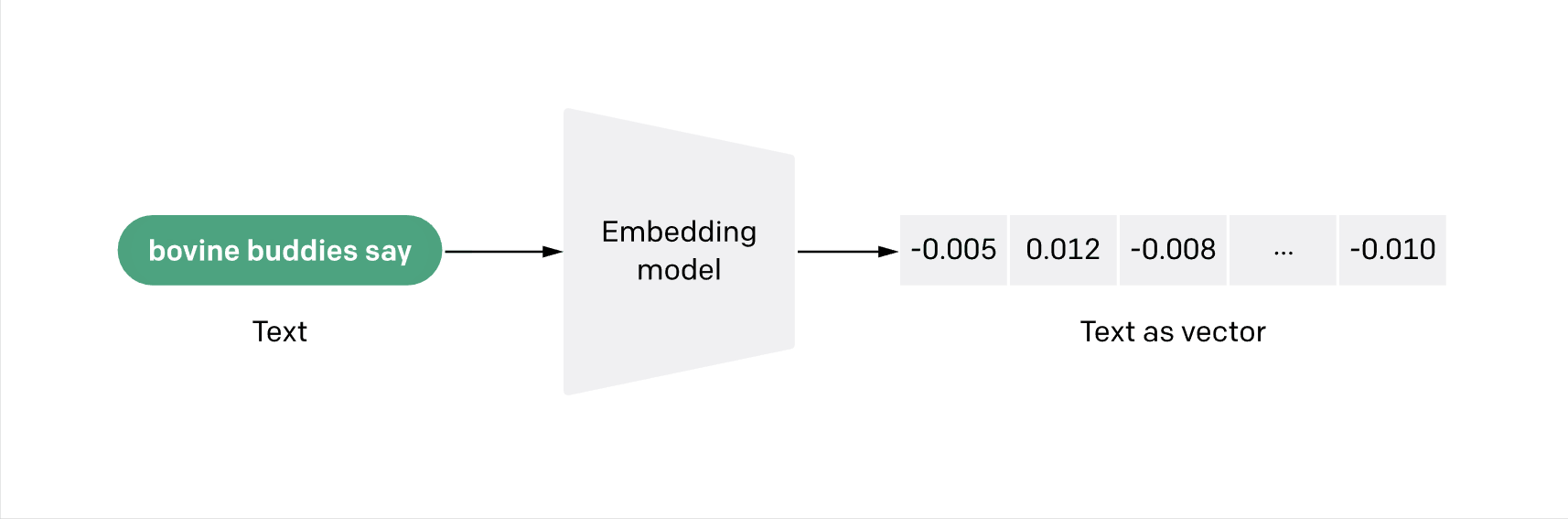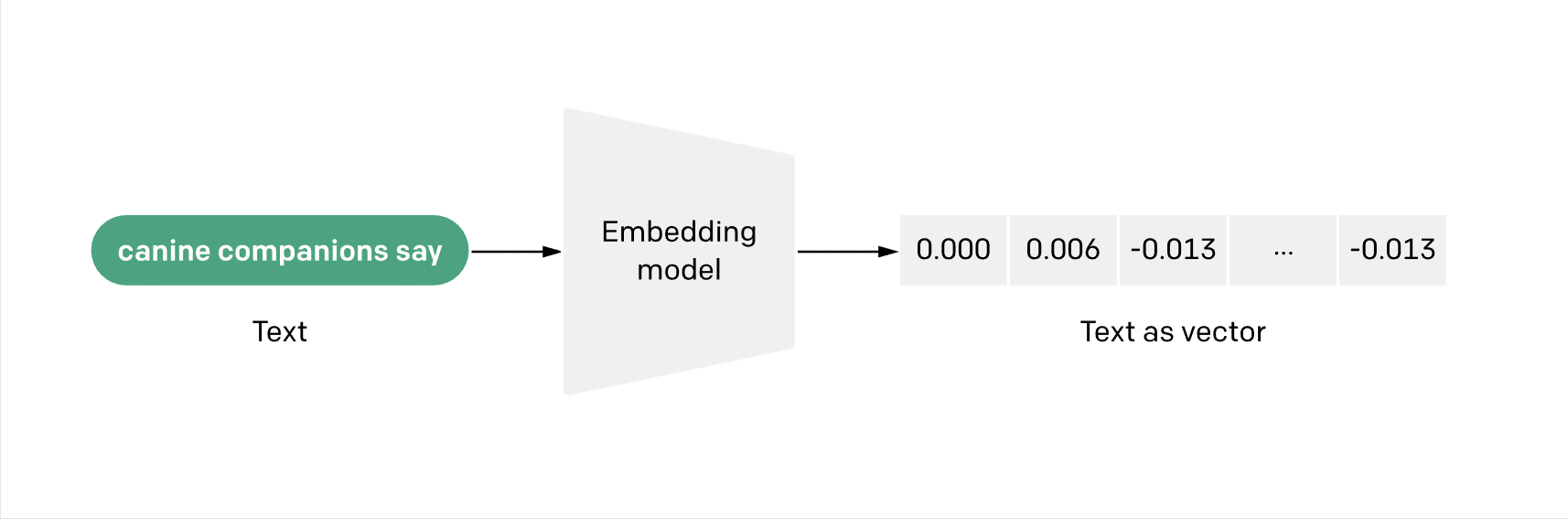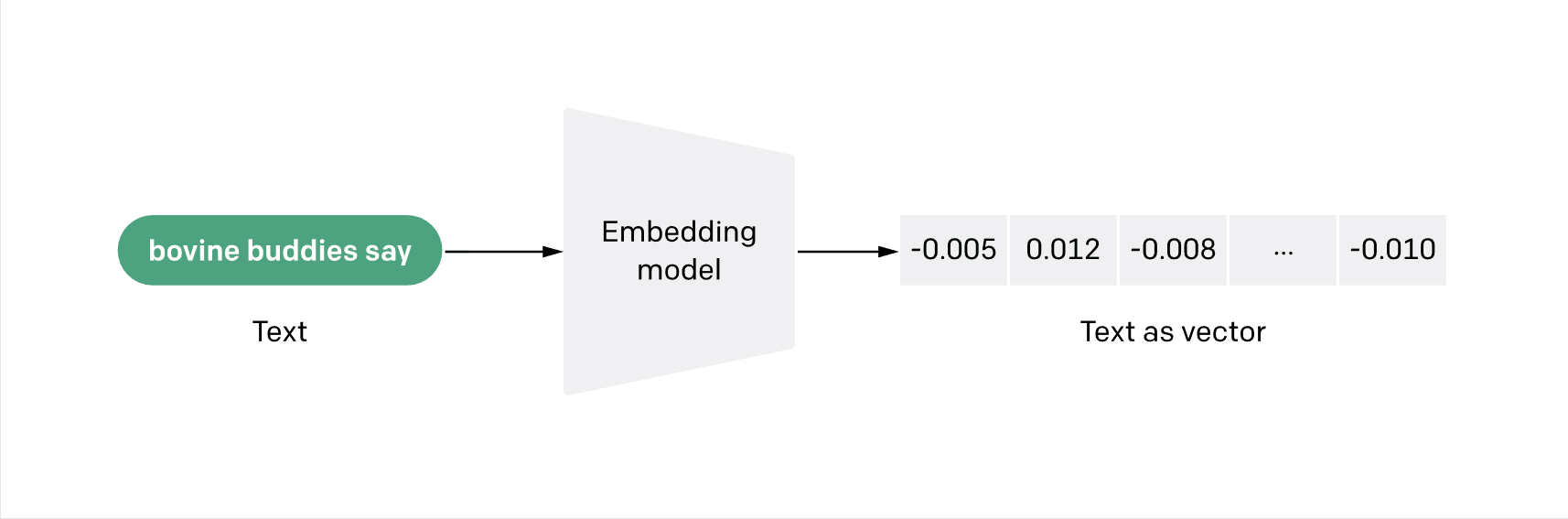
Imagine you have a magical box that can turn words, sentences, and other kinds of information into numbers. These numbers aren’t just any numbers; they’re special because they capture the essence and connections of the information they represent.
Think of it like turning the ideas and meanings behind words into a numerical code.
This ‘magical box’ arranges these codes in an invisible, multi-layered space. Words and ideas that are similar to each other end up being close together. This way, when a computer looks at these numbers, it can understand what the words mean and see how they’re related.

Upon testing, however, vectorising such large chunks of data led to inaccuracies. This compounded with GPT-4s token limit.
If the query was too broad, for example, “tell me about all artificial intelligence companies”, we would exceed the token limit and not all information could be passed to the LLM. This led to errors or low-quality answers.
Using folders
The initial method didn’t get the results we had hoped for, so we decided to change the structure of the data. This time, we would create a script that creates a vector database, but this time with all companies organised into folders separated by their company number.
This helped overcome the previous challenges but with one major catch: only one company can be queried at a time. Quite a serious drawback, but one we would have to live with for now.
Prompt Engineering and RAG
We had the data as sorted as it could be for now, so we moved on to prompt engineering. This is a process that helps get better results from generative AI models by helping them to understand a wider range of queries.
Langchain offers support for this, and after experimenting with many different prompts, we got some very promising results and a drastic increase in the accuracy of our answers. Success!
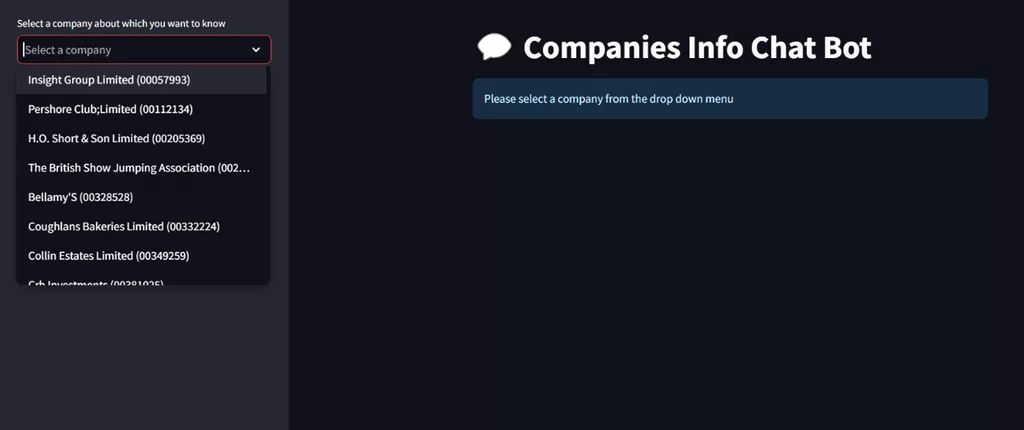
After creating a user-friendly UI (as seen above), we moved on to implementing Retrieval Augmented Generation (RAG).
Essentially, this helps the user to validate whether the answer generated is accurate or not by providing the sources for said answer. As you can probably imagine, this would go a long way in improving the reliability and trustworthiness of the system.
Getting results
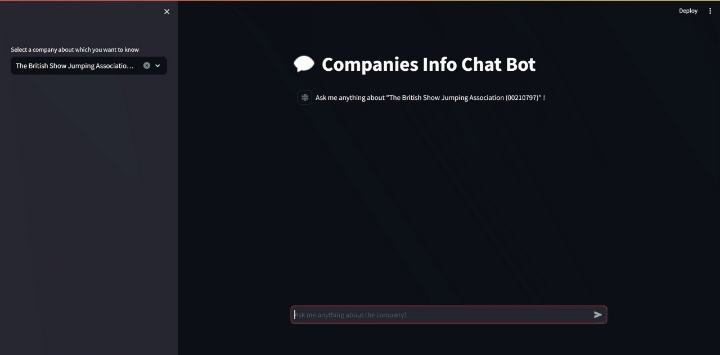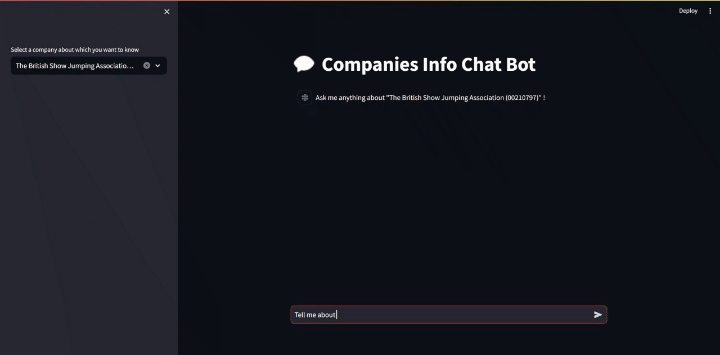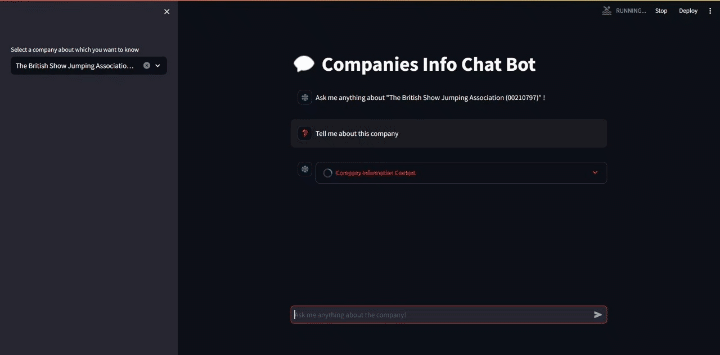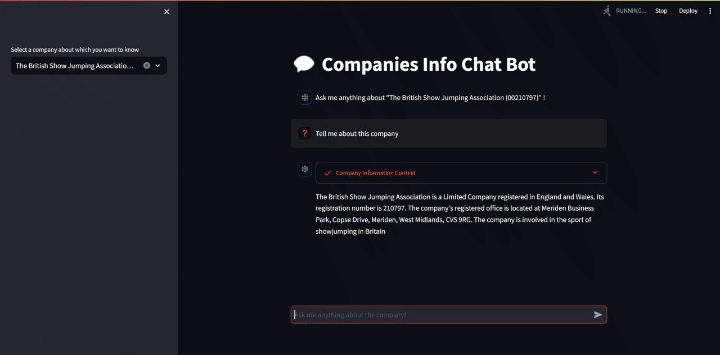
At this point in the project, we’ve reached a point where we can query the LLM about a company and get back good results.
As a showcase, I’ll query the company “The British Show Jumping Association” and ask to tell me about it.
Generating JSON
Until this point, all of our answers had been generated in human-readable sentences and paragraphs. In order to futureproof the system and allow for processing later down the line, we wanted to be able to generate answers in a JSON format.
The first thing we tried was simply modifying the prompts, asking the system to generate responses in JSON instead of sentences. This had mixed results.
While some of the time we got a valid JSON format, a lot of the time we did not. No matter how much we varied the prompts, we could never make it consistent.
Luckily, at this stage in the project, OpenAI had launched chat completion in JSON format. This was the perfect solution and resulted in clean, structured, and validated JSON responses. This greatly streamlined the process, saving us a lot of time.
Conclusion
That’s where we’ve got to so far. This project has served as an excellent starting point to delve deeper into the emerging technologies of Large Language Models. With LLMs advancing at a break-neck pace, we see great potential in utilising this technology in further projects and will continue with our development throughout 2024.
At this point in the project, a user can ask the LLM questions about a single company and get human-readable sentences or JSONs back. It is by far the easiest and quickest way to get information about a specific company.
Our biggest issue currently is speed. We have 1.6m companies, it can take at least a few seconds for each answer. This may not feel like much one-by-one but scaling this up, we don’t have the time to wait that long.
Therefore, our biggest challenge we are eying up at the moment is the potential of a local LLM instead of using OpenAI’s API. With a local LLM, the possibilities are endless, and I am thrilled to lead the charge, leveraging my background in technology and passion for problem-solving to drive our projects forward.