Picture this. You’ve got to identify a song, but you’ve only got a second to do so. It’d be difficult, right?
Music aficionados might be able to get a few, but the accuracy would likely still be low.
Now imagine trying to classify a company using just a couple of words. It’s the same deal; very difficult.
In this blog post, I’m going to explain how The Data City use machine learning to map companies in different sectors.
With us, you get the whole song (or at least most of it). This means we can classify with much higher accuracy.
Exploring the different approaches
I’m going to experiment using the same sector with two different methods.
Keywords
These are specific words or phrases chosen to capture the few important words of the website’s content.
We search website text for keywords. In theory you could apply a keyword approach to a company’s accountancy description, or other text descriptions of a company, but it would be nowhere near as detailed as using website text.
We can search for both positive and negative company keywords in Data Explorer.
Web Text
This refers to all the written information on a website, including headlines, descriptions, and more.
This is our full machine learning function which analyses all of the company web text to understand and classify companies.
Putting keywords to the test
We have the option to filter by website keywords in most parts of the platform. You enter keywords and the system finds companies which have those keywords in their web text.
We can enter any keyword – this is not a pre-defined list. You can also use more advanced techniques, as we’ll get into.
For this test, I will be using the AI (artificial intelligence) sector.
Step 1 – Simple keyword search
Quick but not accurate; lots of companies, lots of noise.
This approach involves searching for companies using keywords related to AI, such as “artificial intelligence”.

We got 39,757 companies back.
Although this query processed in under 2 seconds (pretty fast right?), not all AI companies will say the specific phrase “artificial intelligence” on their website.
Many companies mention “artificial intelligence” without specialising in AI, which can lead to irrelevant results. We’re after AI companies but we’re not currently getting that.
Onto step 2.
Step 2 – Using more AI keywords
Increased coverage. Still quick, but not accurate; way more noise.
This time, we’re using many more keywords. This makes the explorer capture more companies that have any Artificial intelligence-related keywords on their web text.
The main issue is that it does not specifically capture the type of companies we want. We’re after just companies working with artificial intelligence.

We’ve got loads more companies this time – just under 113,150. But now there’s going to be even more irrelevant ones.
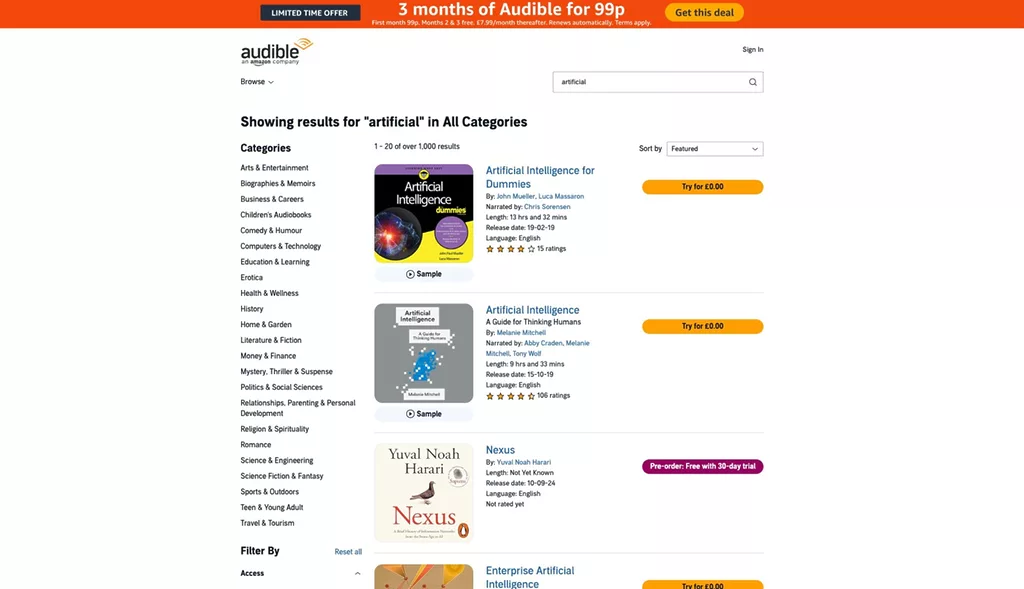
E.g. 1 Audible – an audiobook and podcast platform that offer AI-related content.
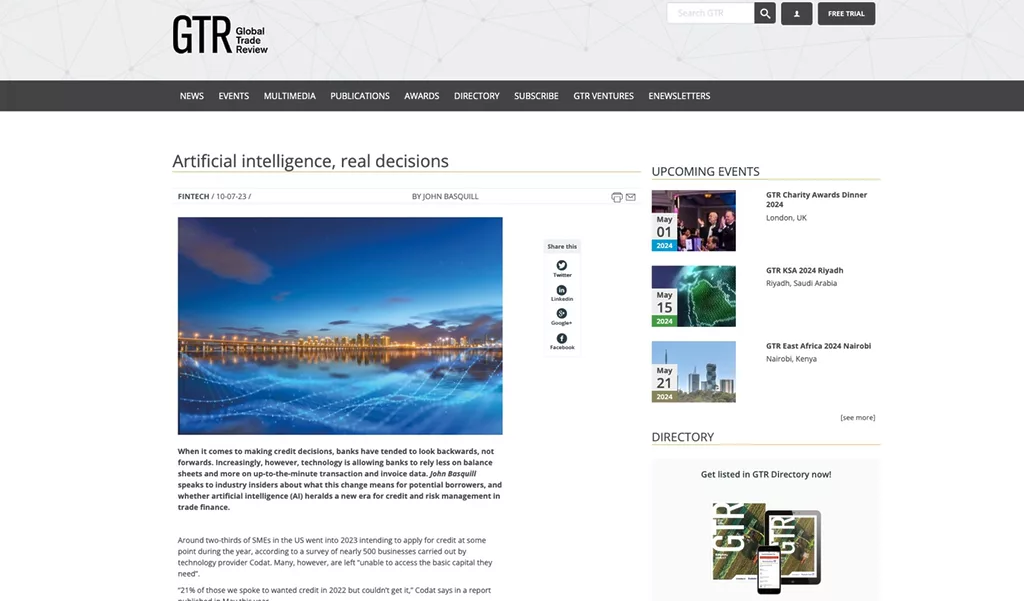
E.g.2. Global Trade Review – an independent publishing and events company offering news, events, and services about global trade, some of which cover AI.

E.g.3. Scholar publishing – a publishing company that have published AI-related books.
Not what we’re looking for. Onto step 3.
Step 3 – Complex keyword filter
Combining multiple keywords. Still quick, but not accurate; reduced noise.
Here’s an example of some combined keywords (Keywords for AI companies that are into medicine):
(“artificial intelligence” OR “ai” OR “a i” OR “neural networks” OR “deep learning” OR “machine learning”) AND (“MEDtech” OR “biotech”* OR “biology” OR “cancer” OR “drug” OR “threap”* OR “patient” OR “diagnostic” OR NEAR(“scienc”* “discover”*, 5) OR “biomarker”* OR “drug”* OR “treatment” OR “healthcare” OR “health” OR “precision medicine” OR “life science”* OR “chemistry” OR “pharma”)
Following the approach, described in our knowledge base article on ‘Using Keyword Filters,’ we combined keywords related to artificial intelligence using a logical search.

This time, we got 89,939 companies. We’ve reduced the noise here, but keywords are limiting us to finding only companies matching our search.
Whilst this identified some relevant companies, a few challenges remain:
- Some companies may have two or more AI-related keywords on their website but are not actually involved in AI applications.
- Relevant companies may not even say any of this. They might not even know they are an AI company. They might be a biotech company that uses machine learning, for example.
- You could manually assign keywords to companies to better reflect their activities, but this would take a massive amount of manual work, coverage will be lower, and the keywords that represent a sector will change over time leading to future inaccuracies.
Using machine learning
Now we move onto machine learning list building, the flagship technology behind our RTICs.
With the help of an industry expert, our Artificial Intelligence RTIC is built from many different verticals. Each vertical will capture a different pocket of AI activity. Read more about how we built the AI RTIC with Innovate UK KTN.
To train the machine learning model, we provide companies from the relevant industry as the training set. During training, the model does not just focus on keywords. Instead, it examines the entire web content of over the 1.6 million URL-matched companies in our database.
It compares each company’s content to others to identify common language and information patterns. By searching for similarities, the model establishes meaningful connections between them. We talk more about how we do it in our knowledge base and on our blog.
See the difference for yourself:

Now we have a focused list of just 3,588 companies out of the 113,150 initially obtained using keywords.
These aren’t just companies that mention “AI” in a blog post, they’re companies that have shown a consistent pattern of using artificial intelligence terminology. This means very little noise and very high accuracy.
How do all of these methods compare?
We can compare the various keyword approaches that we’ve used above to the results that we get with our RTICs.
The comparison is shown below. Using keywords we identify 30-41% of the companies that are in our artificial intelligence RTIC.
This happens for two reasons. Firstly, we’re able to offer a more detailed view of the artificial intelligence sector by representing the sector with 11 verticals. These 11 verticals cover the applications of artificial intelligence. You could use keywords to represent these verticals too, but you would need a lot more keywords.
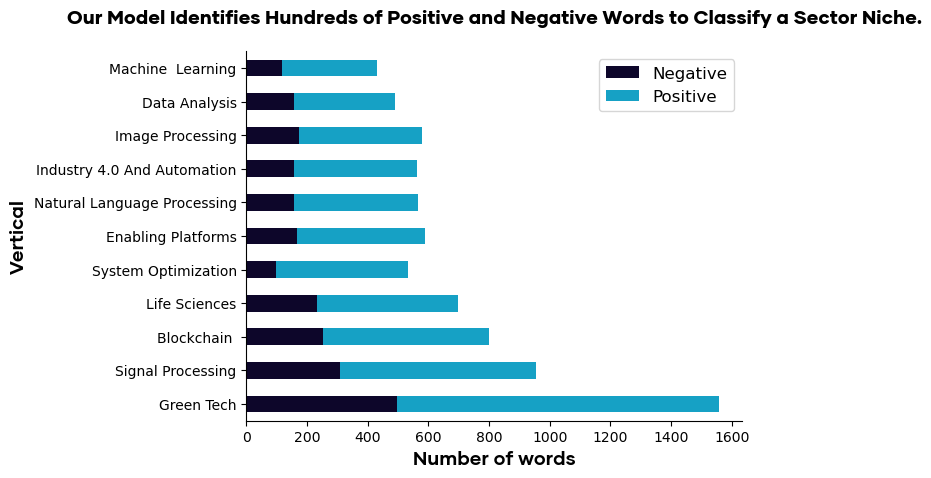
By identifying positive and negative examples of companies in the sector, our model makes use of over 7,000 words to accurately describe the sector.
Importantly, this is a mixture of positive and negative words. Positive words increase the likelihood of a company being included in the sector. For example, a company talking about artificial intelligence is more likely to be in the AI sector. Pretty simple stuff.
The value add is in also having negative keywords.
From the example earlier, we know that companies can be blogs, publishers, or bookshops talking about AI. When our model is trained, it knows to include words like these as negative words; companies mentioning ‘store’ or ‘shopping cart’ are more likely to be excluded from the sector.
Having negative words massively improves the accuracy of the classification and removes the need to validate thousands of companies.
Not to mention that RTICs are also regularly refreshed, and, since they are based of company web text, they will evolve as the companies in the sector evolve. Large Language Models become the talk of the town in AI? RTICs will capture that.
In addition to the fact that they are built with industry experts means that they are classifications you can trust.
Summary
The Downside of Keywords:
Limited Understanding: Keywords are just single words or short phrases. They cannot capture the full context or meaning of a company’s web content. Our competitors can be too reliant on keywords.
Imagine searching for “cloud” – it could be about meteorology, and understanding weather patterns, or it could refer to cloud computing, managing data and applications over the internet.
Keywords often miss these subtleties and fail to capture the specific context and semantic information needed for accurate results.
The Power of Full Web Text:
Richer Context: By analysing the entire web text, the machine learning algorithm can understand the bigger picture. It can see how keywords are used within sentences, paragraphs, and the website overall.
This allows for a more nuanced understanding of a company’s industry and offerings.
Reduced Noise: By looking at the complete content, our machine learning can filter out irrelevant matches. It can differentiate between a company selling running shoes and a company mentioning “running shoes” in a blog post about exercise.
This reduces noise and leads to more accurate connections.
Concluding
Many other company databases rely solely on keyword or buzzword-based methodologies to build industry lists; these are not true classifications.
At The Data City, we use machine learning to understand companies better than anyone else. We don’t just look at a few keywords, we read the entire web text.
Don’t try to identify the song using only a few seconds, get the full thing.
Try out our platform for free by signing up for a free trial.