Let’s dive into part 3 of our series dedicated to sharing a behind-the-scenes peek of the development of our Industry Engine.
In this post we are going to turn the spotlight on our new, soon to be released, Smart Search capability (Introduced in this series’ first post). This feature will enable our users to search the entire UK business base using keywords, phrases, concepts, and even complete sentences, drastically improving the discoverability of companies.
If you haven’t already, take a look at the second post in this series before you read on. You’ll find our Semantic Search explainer from part 2 useful here.
What’s new?
We have data for over 5 million companies. That’s a lot of data. We often need to be able to cut through this vast dataset and search for what we’re interested in.
We currently rely on keyword searching to identify companies of interest, looking for those with websites that contain these exact words. This is relatively straightforward: the more your keywords match the text on a website, the more likely that website is to appear in your results.
However, in a semantic search, the system is trying to match the meaning and context of your sentence to the meanings and context of entire web pages.
We’ve used these ideas to power our new similarity functionality – and now we are extending this capability to allow our users to use the same LLM-based technology to do their own searches of our company data.
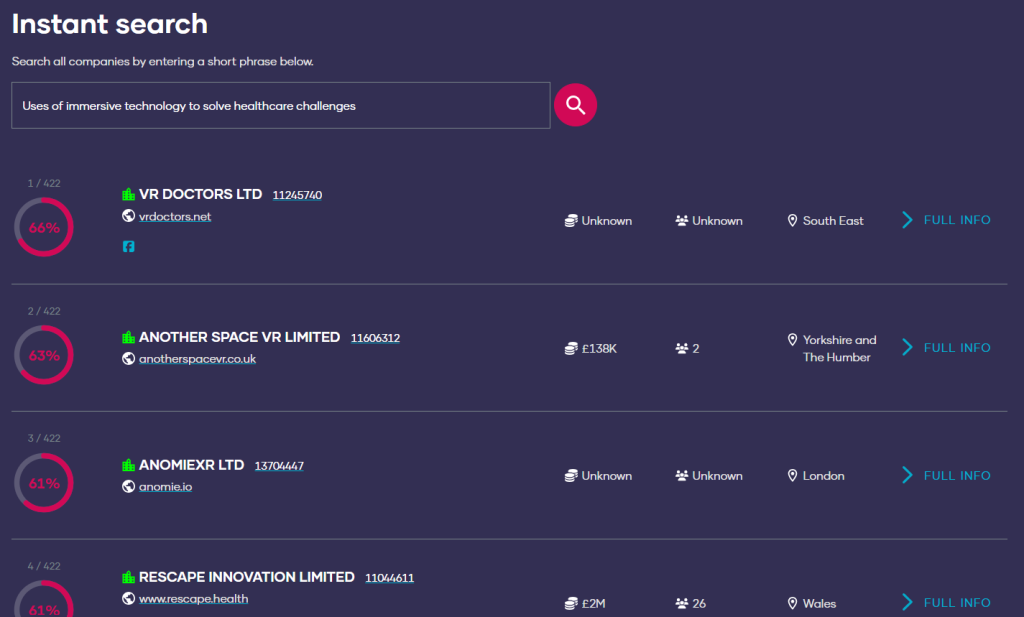
When you search using a sentence in our system, you’re not just matching words with those on company websites, as you would with a typical keyword search.
Instead, the system tries to understand the meaning of your sentence and finds website pages that are semantically similar—that is, pages that convey similar ideas or information, even if they don’t use the exact same words.
How is it useful?
This is especially useful when looking for companies in emerging sectors where the hot topics are constantly developing, and buzz words come and go. Or even in identifying sectors which use phrases synonymously to convey the same thing (think “recruitment”, “head-hunting”, “candidate resourcing”, “talent acquisition”, etc.).
It also could be used as another resource in the initial phase of ML list building, offering as an alternative to a keyword taxonomy when seeking to identify relevant companies in the development of training sets.
How does it work and what’s possible?
Although we have all taken ChatGPT in as part of our families, don’t let its ease-of-use fool you, LLM transformers are complex beasts. They process more than just words. Context, relationships between concepts, and even the specific way companies present their information can all influence the results. Because of this, it can be hard to predict which pages will be considered “similar” to your input query.
It therefore takes some consideration when coming up with search phrase to get to what you’re looking for. It’s both an art and a science. To get the best results, think about the overall idea or message you want the web pages to match, rather than focusing on specific words. Here are some tips:
Be Specific: The more specific your sentence, the better the system can narrow down the search.
Context Matters: Include relevant context or details that are central to the idea you’re searching for. This helps the system understand what aspect of the company information you’re interested in.
Try Different Phrasings: If the results aren’t what you expected, try rephrasing your sentence. Since the system matches based on meaning, slightly different wording can lead to different, potentially better results.
Test and Learn: Over time, you’ll get a feel for how the system responds to different types of queries. Experiment with different sentences to see which ones yield the most relevant website pages.
We’re still early in the beginner squad ourselves, playing around to see what works, and what’s less successful.
What’s next?
Now that we have this first pass, we are keen to build on it, and we’re working hard to improve and develop it.
Perfecting how to use it: We’re playing around with it ourselves, learning how to best use it, and what its scope is. Can it just look for what a company does, its services and products, or can it successfully identify companies based on other information, such as corporate values? We’re still exploring.
Next-stage developments: As we explore, we’re asking, when are poor results a result of poor use, and when do they indicate room for improvement in the underlying model? Then we are seeking to make those improvements.
This is not just an LLM wrapper, we’ve developed an end-to-end LLM-based information retrieval system for UK businesses. Achieving this on text data for over 1.7million companies has been a technical and computational challenge. But the possibilities are great, too. For instance, as LLMs continue to develop at pace, we’re keeping on top of advancements, exploring emerging and improved transformers to identify those most capable at handling this size data, and those most appropriate for semantic search.
Hopefully, this continued R&D will be evident in gradually more improved and refined search results. But as a first attempt, we are happy. It already mostly gives sensible results, given a sensible search phrase, and we’re already seeing its uses internally. And very soon, you’ll be able to explore it for yourselves.
If you have any feedback or any suggestions for new features, we could enable with them please let us know.
Want to try it out for yourself? Sign up to a free trial here.


